Apache Spark 3.5 Tutorial with Examples
In this Apache Spark Tutorial for Beginners, you will learn Spark version 3.5 with Scala code examples. All Spark examples provided in this Apache Spark Tutorial for Beginners are basic, simple, and easy to practice for beginners who are enthusiastic about learning Spark, and these sample examples were tested in our development environment.
Note: If you can’t find the spark sample code example you are looking for on this tutorial page, I would recommend using the Search option from the menu bar to find your tutorial.
- What is Apache Spark
- Features & Advantages
- Architecture
- Installation
- RDD
- DataFrame
- SQL
- Data Sources
- Streaming
- GraphFrame
What is Apache Spark?
Apache Spark Tutorial – Apache Spark is an Open source analytical processing engine for large-scale powerful distributed data processing and machine learning applications. Spark was Originally developed at the University of California, Berkeley’s, and later donated to the Apache Software Foundation. In February 2014, Spark became a Top-Level Apache Project and has been contributed by thousands of engineers making Spark one of the most active open-source projects in Apache.
Apache Spark 3.5 is a framework that is supported in Scala, Python, R Programming, and Java. Below are different implementations of Spark.
- Spark – Default interface for Scala and Java
- PySpark – Python interface for Spark
- SparklyR – R interface for Spark.
Examples explained in this Spark tutorial are with Scala, and the same is also explained with PySpark Tutorial (Spark with Python) Examples. Python also supports Pandas which also contains Data Frame but this is not distributed.
Features of Apache Spark
- In-memory computation
- Distributed processing using parallelize
- Can be used with many cluster managers (Spark, Yarn, Mesos e.t.c)
- Fault-tolerant
- Immutable
- Lazy evaluation
- Cache & persistence
- Inbuild-optimization when using DataFrames
- Supports ANSI SQL
Advantages of Apache Spark
- Spark is a general-purpose, in-memory, fault-tolerant, distributed processing engine that allows you to process data efficiently in a distributed fashion.
- Applications running on Spark are 100x faster than traditional systems.
- You will get great benefits from using Spark for data ingestion pipelines.
- Using Spark we can process data from Hadoop HDFS, AWS S3, Databricks DBFS, Azure Blob Storage, and many file systems.
- Spark also is used to process real-time data using Streaming and Kafka.
- Using Spark Streaming you can also stream files from the file system and also stream from the socket.
- Spark natively has machine learning and graph libraries.
- Provides connectors to store the data in NoSQL databases like MongoDB
What Versions of Java & Scala Spark 3.5 Supports?
Apache Spark 3.5 is compatible with Java versions 8, 11, and 17, Scala versions 2.12 and 2.13, Python 3.8 and newer, as well as R 3.5 and beyond. However, it’s important to note that support for Java 8 versions prior to 8u371 has been deprecated starting from Spark 3.5.0.
| LANGUAGE | SUPPORTED VERSION |
|---|---|
| Python | 3.8 |
| Java | Java 8, 11, 13, 17, and the latest versions Java 8 versions prior to 8u371 have been deprecated |
| Scala | 2.12 and 2.13 |
| R | 3.5 |
Apache Spark Architecture
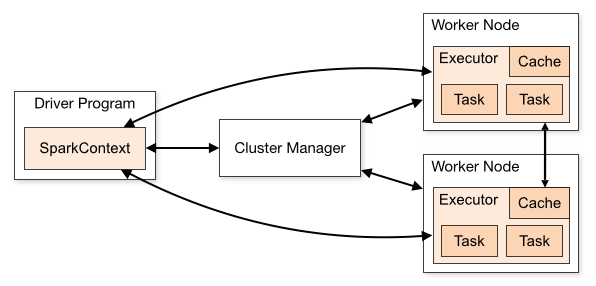
Cluster Manager Types
- Standalone – a simple cluster manager included with Spark that makes it easy to set up a cluster.
- Apache Mesos – Mesons is a Cluster manager that can also run Hadoop MapReduce and Spark applications.
- Hadoop YARN – the resource manager in Hadoop 2. This is mostly used, a cluster manager.
- Kubernetes – an open-source system for automating deployment, scaling, and management of containerized applications.
master() in order to run Spark on our laptop/computer. Spark Installation
In order to run the Apache Spark examples mentioned in this tutorial, you need to have Spark and its needed tools to be installed on your computer. Since most developers use Windows for development, I will explain how to install Spark on Windows in this tutorial. you can also Install Spark on a Linux server if needed.
Related: Spark Installation on Mac (macOS)
Download Apache Spark by accessing the Spark Download page and selecting the link from “Download Spark (point 3)”. If you want to use a different version of Spark & Hadoop, select the one you wanted from dropdowns, and the link on point 3 changes to the selected version and provides you with an updated link to download.

After downloading, untar the binary using 7zip and copy the underlying folder spark-3.5.0-bin-hadoop3 to c:\apps
Now set the following environment variables.
SPARK_HOME = C:\apps\spark-3.5.0-bin-hadoop3
HADOOP_HOME = C:\apps\spark-3.5.0-bin-hadoop3
PATH=%PATH%;C:\apps\spark-3.0.5-bin-hadoop3\bin
Setup winutils.exe
spark-shell
RDD Spark Tutorial
RDD (Resilient Distributed Dataset) is a fundamental data structure of Spark and it is the primary data abstraction in Apache Spark and the Spark Core. RDDs are fault-tolerant, immutable distributed collections of objects, which means once you create an RDD you cannot change it. Each dataset in RDD is divided into logical partitions, which can be computed on different nodes of the cluster.
This Apache Spark RDD Tutorial will help you start understanding and using Apache Spark RDD (Resilient Distributed Dataset) with Scala code examples. All RDD examples provided in this tutorial were also tested in our development environment and are available at GitHub spark scala examples project for quick reference.
In this section of the Apache Spark tutorial, I will introduce the RDD and explain how to create them and use their transformation and action operations. Here is the full article on Spark RDD in case you want to learn more about it and get your fundamentals strong.
RDD creation
sparkContext.parallelize()
sparkContext.parallelize is used to parallelize an existing collection in your driver program. This is a basic method to create RDD.
//Create RDD from parallelize
val dataSeq = Seq(("Java", 20000), ("Python", 100000), ("Scala", 3000))
val rdd=spark.sparkContext.parallelize(dataSeq)
sparkContext.textFile()
Using textFile() method we can read a text (.txt) file from many sources like HDFS, S#, Azure, local e.t.c into RDD.
RDD Operations
//Create RDD from external Data source
val rdd2 = spark.sparkContext.textFile("/path/textFile.txt")
On Spark RDD, you can perform two kinds of operations.
RDD Transformations
RDD Actions
RDD Examples
DataFrame Spark Tutorial with Basic Examples
DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as structured data files, tables in Hive, external databases, or existing RDDs. – Databricks
DataFrame creation
The simplest way to create a Spark DataFrame is from a seq collection. Spark DataFrame can also be created from an RDD and by reading files from several sources.
using createDataFrame()
By using createDataFrame() function of the SparkSession you can create a DataFrame.
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types._
// Create SparkSession
val spark = SparkSession.builder()
.appName("Employee DataFrame Example")
.master("local[*]")
.getOrCreate()
// Sample data
val data = Seq(
Row(101, "Alice", "Data Engineer", 85000.50),
Row(102, "Bob", "ML Engineer", 92000.00),
Row(103, "Charlie", "DevOps", 78000.75),
Row(104, "Diana", "Analyst", 65000.00)
)
// Define schema
val schema = StructType(Seq(
StructField("employee_id", IntegerType, nullable = false),
StructField("name", StringType, nullable = false),
StructField("role", StringType, nullable = false),
StructField("salary", DoubleType, nullable = true)
))
// Create DataFrame
val df = spark.createDataFrame(spark.sparkContext.parallelize(data), schema)
// Show output
df.show()
+-----------+-------+-------------+--------+
|employee_id| name | role | salary |
+-----------+-------+-------------+--------+
| 101| Alice |Data Engineer|85000.5 |
| 102| Bob | ML Engineer |92000.0 |
| 103|Charlie| DevOps |78000.75|
| 104| Diana | Analyst |65000.0 |
+-----------+-------+-------------+--------+
In this Apache Spark SQL DataFrame Tutorial, I have explained several mostly used operation/functions on DataFrame & DataSet with working Scala examples.
- Spark DataFrame – Rename nested column
- How to add or update a column on DataFrame
- How to drop a column on DataFrame
- Spark when otherwise usage
- How to add literal constant to DataFrame
- Spark Data Types explained
- How to change column data type
- How to Pivot and Unpivot a DataFrame
- Create a DataFrame using StructType & StructField schema
- How to select the first row of each group
- How to sort DataFrame
- How to union DataFrame
- How to drop Rows with null values from DataFrame
- How to split single to multiple columns
- How to concatenate multiple columns
- How to replace null values in DataFrame
- How to remove duplicate rows on DataFrame
- How to remove distinct on multiple selected columns
- Spark map() vs mapPartitions()
Spark DataFrame Advanced concepts
Spark Data Source with Examples
Spark SQL supports operating on a variety of data sources through the DataFrame interface. This section of the tutorial describes reading and writing data using the Spark Data Sources with Scala examples. Using Data source API we can load from or save data to RDMS databases, Avro, parquet, XML etc.
Text
CSV
JSON
JSON’s readability, flexibility, language-agnostic nature, and support for semi-structured data make it a preferred choice in big data Spark applications where diverse sources, evolving schemas, and efficient data interchange are common requirements.
Key characteristics and reasons why JSON is used in big data include Human-Readable Format, Language-Agnostic, Semi-Structured Data, Schema Evolution e.t.c
Spark Streaming Tutorial & Examples
Spark Streaming is a scalable, high-throughput, fault-tolerant streaming processing system that supports both batch and streaming workloads. It is used to process real-time data from sources like file system folders, TCP sockets, S3, Kafka, Flume, Twitter, and Amazon Kinesis to name a few. The processed data can be pushed to databases, Kafka, live dashboards e.t.c

- Spark Streaming – OutputModes Append vs Complete vs Update
- Spark Streaming – Read JSON Files From Directory with Scala Example
- Spark Streaming – Read data From TCP Socket with Scala Example
- Spark Streaming – Consuming & Producing Kafka messages in JSON format
- Spark Streaming – Consuming & Producing Kafka messages in Avro format
- Using from_avro and to_avro functions
- Reading Avro data from Kafka topic using from_avro() and to_avro()
- Spark Batch Processing using Kafka Data Source
Spark – HBase Tutorials & Examples
Spark with Kafka Tutorials
In this section of the Spark Tutorial, you will learn several Apache HBase spark connectors and how to read an HBase table to a Spark DataFrame and write DataFrame to HBase table.
Apache HBase is an open-source, distributed, and scalable NoSQL database that runs on top of the Hadoop Distributed File System (HDFS). It provides real-time read and write access to large datasets and is designed for handling massive amounts of unstructured or semi-structured data, making it suitable for big data applications.
SQL Spark Tutorial
Spark SQL is one of the most used Spark modules which is used for processing structured columnar data format. Once you have a DataFrame created, you can interact with the data by using SQL syntax. In other words, Spark SQL brings native RAW SQL queries on Spark meaning you can run traditional ANSI SQL on Spark Dataframe. In the later section of this Apache Spark tutorial, you will learn in detail using SQL select, where, group by, join, union e.t.c
In order to use SQL, first, we need to create a temporary table on DataFrame using createOrReplaceTempView() function. Once created, this table can be accessed throughout the SparkSession and it will be dropped along with your SparkContext termination.
On a table, SQL query will be executed using sql() method of the SparkSession and this method returns a new DataFrame.
df.createOrReplaceTempView("PERSON_DATA")
val df2 = spark.sql("SELECT * from PERSON_DATA")
df2.printSchema()
df2.show()
This yields the below output
val groupDF = spark.sql("SELECT gender, count(*) from PERSON_DATA group by gender")
groupDF.show()
+------+--------+
|gender|count(1)|
+------+--------+
| F| 2|
| M| 3|
+------+--------+
Similarly, you can run any traditional SQL queries on DataFrames using Spark SQL.
Spark GraphX and GraphFrames
Spark GraphFrames are introduced in Spark 3.0 version to support Graphs on DataFrames. Prior to 3.0, Spark had GraphX library which ideally runs on RDD, and lost all Data Frame capabilities.
GraphFrames is a graph processing library for Apache Spark that provides high-level abstractions for working with graphs and performing graph analytics. It extends Spark’s DataFrame API to support graph operations, allowing users to express complex graph queries using familiar DataFrame operations.
Below is an example of how to create and use Spark GraphFrame.
// Import necessary libraries
import org.apache.spark.sql.SparkSession
import org.graphframes.GraphFrame
// Create a Spark session
val spark = SparkSession.builder.appName("GraphFramesExample").getOrCreate()
// Define vertices and edges as DataFrames
val vertices = spark.createDataFrame(Seq(
(1, "Scott", 30),
(2, "David", 40),
(3, "Mike", 45)
)).toDF("id", "name", "age")
val edges = spark.createDataFrame(Seq(
(1, 2, "friend"),
(2, 3, "follow")
)).toDF("src", "dst", "relationship")
// Create a GraphFrame
val graph = GraphFrame(vertices, edges)
// Display vertices and edges
graph.vertices.show()
graph.edges.show()
// Perform Graph Queries
val aliceFriends = graph.edges.filter("src = 1").join(graph.vertices, "dst").select("dst", "name")
aliceFriends.show()
// Graph Analytics - In-degrees
val inDegrees = graph.inDegrees
inDegrees.show()
// Subgraph Creation
val subgraph = graph.filterVertices("age >= 40").filterEdges("relationship = 'friend'")
subgraph.vertices.show()
subgraph.edges.show()
// Graph Algorithms - PageRank
val pageRankResults = graph.pageRank.resetProbability(0.15).maxIter(10).run()
pageRankResults.vertices.show()
pageRankResults.edges.show()
// Stop the Spark session
spark.stop()